 VIPC6资源网
VIPC6资源网
本套课程:(CDA)最快的数据获取方式-Python爬虫,课程官方售价499元, 本套课程零基础Python爬虫系列,10章节课程带你快速入门Python,掌握编写网络爬虫程序,非常适合小白学习,本课程包含视频课件与源码资料, 文章底部附下载地址。
课程介绍:
本课程共分为三个部分:分别是:
一、初始爬虫及必备知识
1. Python安装及介绍
2. Python编程基础
3. HTML,HTTP,Chrome开发者工具
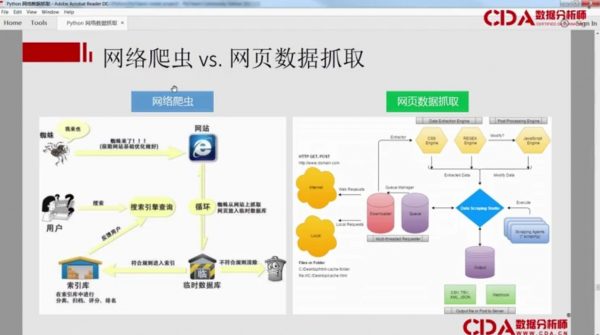
最快的数据获取方式-Python爬虫 视频截图
二、网络爬虫核心知识
1. 网络请求:Requests
2. 解析HTML文档- BeautifulSoup
3. 反爬虫及异常处理
4. 数据存储- TEXT, CSV
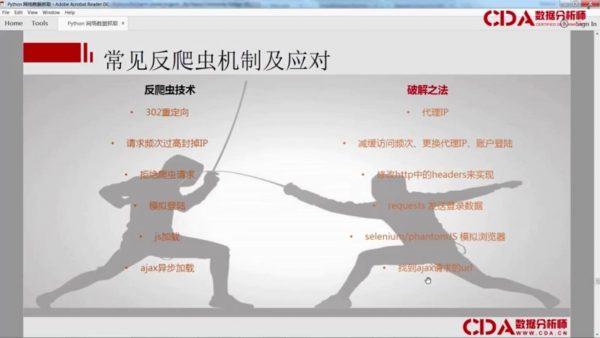
最快的数据获取方式-Python爬虫 视频截图
三、网络爬虫实战案例
1. 案例:抓取多个网页头像
2. 案例:抓取书籍简介
3. 案例:利用API获取招聘信息
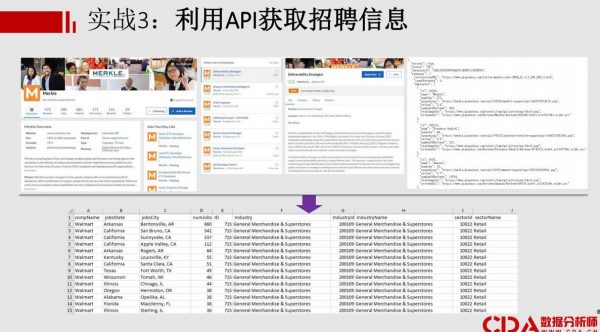
最快的数据获取方式-Python爬虫 课件截图
课程文件目录:V-3172:最快的数据获取方式-Python爬虫 [1.6G]
任务1:0 – 课程大纲.mp4
任务2:1-1 – Python概述,应用,特点及发展趋势.mp4
任务3:1-2 – Python解释器及其专业级集成开发软件PyCharm的安装.mp4
第2节 Python编程基础
任务10:2-7 – 基础编程-数据存储-TEXT,CSV,Sqlite.mp4
任务4:2-1 – 基础编程-变量.mp4
任务5:2-2 – 基础编程-数字,字符串.mp4
任务6:2-3 – 基础编程-列表,元组,字典.mp4
任务7:2-4 – 基础编程-自定义函数.mp4
任务8:2-5 – 基础编程-错误与异常处理.mp4
任务9:2-6 – 基础编程-模块安装,引入和管理.mp4
第3节 初始爬虫及必备知识- HTML,HTTP,Chrome开发者工具
任务11:3 – 网络爬虫必备基础知识.mp4
第4节 网络请求- requests
任务12:4-1 – 网络请求 – requests之快速上手.mp4
任务13:4-2 – 网络请求 – requests之高级方法.mp4
第5节 解析HTML文档- BeautifulSoup
任务14:5-1 – HTM文档解析利器BeautifulSoup的安装及HTML文档树.mp4
任务15:5-2 – HTML文档树的遍历和搜索-find系列方法.mp4
任务16:5-3 – HTML文档树的搜索-CSS Selector方法.mp4
第6节 反爬虫及异常处理
任务17:6 – 通过API获取数据.mp4
第7节 数据存储- TEXT, CSV
任务18:7 – 网络爬虫进阶-常见的反爬虫机制及应对方法.mp4
第8节 实战1- 抓取头像
任务19:8-1 – 实战1 – 头像批量下载.mp4
第9节 实战2- 抓取书籍简介
任务20:8-2 – 实战2 – 批量下载书籍简介.mp4
第10节 实战3- 利用 API 获取招聘信息
任务21:8-3 – 实战3 – 通过API抓取招聘网站招聘信息并保存在数据库中.mp4
任务22:9 – 课程内容回顾.mp4
Python 网络数据抓取代码.zip
Python 网络数据抓取课件.pdf
课程下载地址:
VIP用户免C币下载,下载前请阅读上方文件目录,下载链接为百度云网盘,如链接失效,可评论告知。